Discover the ultimate guide to mastering the ChatGPT API in your applications. From basic configuration to advanced customizations, this article gives you a complete overview to make the most of the capabilities of this revolutionary language model.
Artificial intelligence and natural language processing have taken the technology world by storm, opening doors to applications and services that we would never have imagined a few years ago. At the heart of this revolution is ChatGPT, a language model developed by OpenAI. In this article, we’ll dive into the details of the ChatGPT API, explore why it’s essential for your applications, and guide you step-by-step to effectively integrate it into your projects. Whether you’re a seasoned developer or a tech enthusiast, this guide is for you.
Prerequisites
Before diving in, it’s important to make sure you have the tools and skills to follow this guide. You will need :
- Basic knowledge of programming, ideally in Python.
- An account on the OpenAI platform. If you don’t have one, don’t worry, we will guide you through the registration process.
Obtain OpenAI API keys
The first step to using the ChatGPT API is to obtain your API keys from OpenAI. To do this, go to the official OpenAI website and log in or register if you don’t have an account yet. Once logged in, navigate to the “Personal” tab located in the upper right section of the page. Select the “View API Keys” option from the drop-down menu. You will then be taken to a page where you can generate a new secret key by clicking on the “Create new secret key” button. Write down this key and keep it safe, as it will not be displayed again.
ChatGPT models
When using the ChatGPT API, you have several models to choose from, including gpt-3.5-turbo and gpt-4. These models are the engines that power ChatGPT’s text generation capabilities. They are optimized for chat tasks, but can also be used for text completion. It should be noted that although the GPT-4 model is the newest and most powerful, it is currently on a waiting list. The gpt-3.5-turbo model, on the other hand, is accessible to everyone and offers excellent value for money compared to previous GPT-3 models.
Basic API setup
Once you have your API key and have chosen your template, it’s time to move on to basic setup. You will need to configure the chat model for your API call. To do this, you can use the Python programming language and the OpenAI library. Here is sample code that demonstrates how to configure an API call:
import openai
openai.api_key = "VOTRE_CLÉ_API"
completion = openai.ChatCompletion.create(
model = "gpt-3.5-turbo",
temperature = 0.8,
max_tokens = 2000,
messages = [
{"role": "system", "content": "Vous êtes un assistant qui raconte des blagues de papa."},
{"role": "user", "content": "Racontez-moi une blague sur les mathématiques."}
]
)
In this example we used the model gpt-3.5-turbo and defined parameters like temperature And max_tokens to control the behavior of the model. To simply experiment without installing a Python development environment, there are online code executors like Replit or Online Python
Advanced customization
ChatGPT’s API is very flexible and allows you to customize your experience in advanced ways. You can use different roles in messages to control the behavior of the assistant. For example, the role system can be used to define context, while role user is used to give instructions to the assistant. You can also adjust settings like temperaturewhich controls the degree of creativity of the assistant, and max_tokenswhich limits the length of responses.
messages = [
{"role": "system", "content": "Vous êtes un assistant qui aide à coder."},
{"role": "user", "content": "Comment créer une boucle en Python ?"}
]
In this example, the role system sets the context by indicating that the assistant should help code, and the role user gives the specific instruction.
Using the Text Completion API
ChatGPT’s API is not only useful for chat tasks. It also excels at text completion, which can be particularly useful for applications like content generators or writing aids. Here’s how you can configure the API for a text completion task:
import openai
openai.api_key = "VOTRE_CLÉ_API"
completion = openai.ChatCompletion.create(
model = "gpt-3.5-turbo",
temperature = 0.8,
max_tokens = 2000,
messages = [
{"role": "system", "content": "Vous êtes un poète qui crée des poèmes émouvants."},
{"role": "user", "content": "Écrivez un court poème sur la solitude."}
]
)
In this example, the role system sets the context by indicating that the assistant is a poet, and the role user gives instructions to create a poem about loneliness.
Building apps with the ChatGPT API
The ChatGPT API offers a multitude of possibilities for application development. Whether you want to create an intelligent chatbot, a marketing content generator, or even a code translation app, the possibilities are almost endless. You can use either the API endpoint directly or the Python or Node.js libraries provided by OpenAI. It is also possible to use community-maintained libraries, although their security is not verified by OpenAI.
API response and format
When you make a call to the ChatGPT API, the response is returned in a specific JSON format. It is crucial to know how to extract the necessary information from this response for use in your application. For example, the response might look like this:
{
"choices": [
{
"message": {
"role": "assistant",
"content": "La solitude est un océan sans fin, où l'âme se perd et se retrouve."
}
}
]
}
In this example, the assistant’s response is stored in the field content of the object messagewhich is part of the table choices.
Problems and limitations
Like any technology, the ChatGPT API is not without its challenges and limitations. For example, models can sometimes generate biased or inappropriate responses. Additionally, there are limits on the number of tokens each model can generate or process. For the gpt-3.5-turbo model, the limit is 4,096 tokens (approximately 8,000 words), while for the gpt-4 model, it is 8,192 tokens (approximately 15,000 words). It is therefore important to take these limitations into account when designing your application.
What if Python is not my cup of tea?
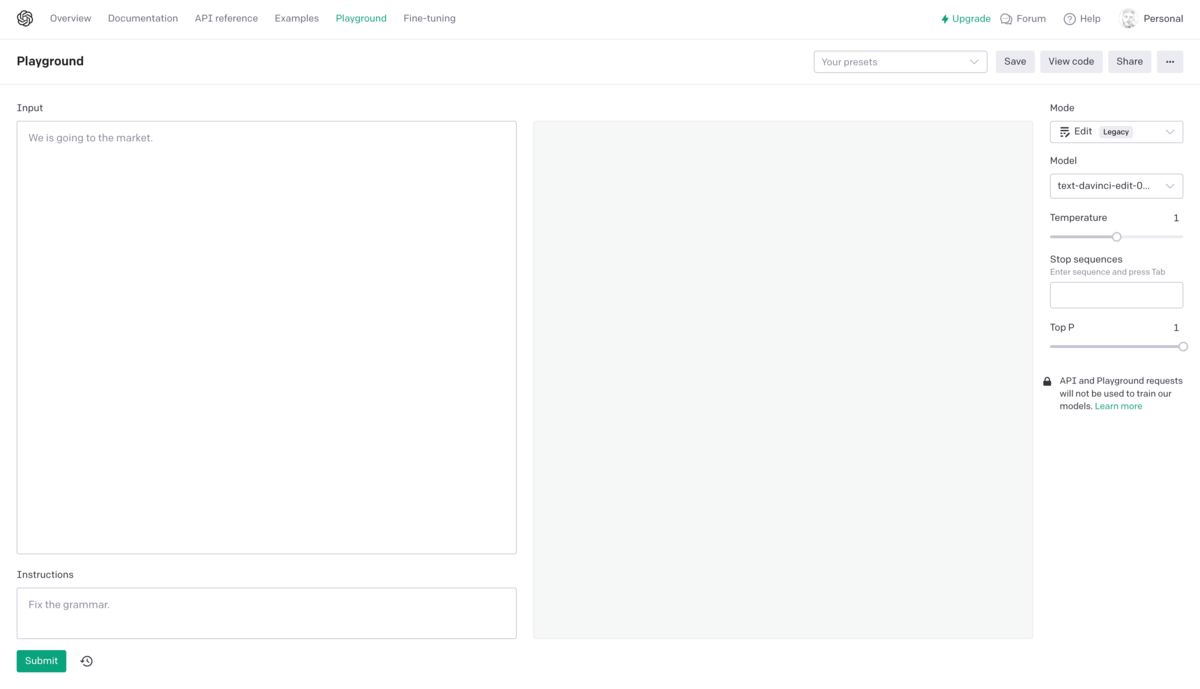
The OpenAI Playground
The Playground allows you to quickly test different configurations without having to write complex code. You can adjust settings such as “temperature”, which controls how creative responses are, or “stop sequences”, which determine when a generated response should end. This flexibility is particularly useful for developers and researchers who want to experiment before deploying a model in a real application.
Understanding the model
The Playground also offers a way to gain a deeper understanding of the model you are using. By observing how the model reacts to different guests and settings, you can gain valuable information about its strengths and weaknesses. This can help you choose the most appropriate model for your specific application.
Cost and effectiveness
Finally, the Playground can also be used as a tool to assess the cost of using a particular model. Different models have different usage costs, and the Playground allows you to do preliminary testing to assess the cost-effectiveness of the model you are considering using.
Detailed explanation of OpenAI Playground settings
Temperature
“Temperature” is a parameter that controls the degree of creativity or variability of the responses generated by the model. A higher value (closer to 1) will make responses more random and creative, while a lower value (closer to 0) will make responses more deterministic and focused on the most likely text.
- High value (close to 1): More creative but potentially less coherent responses.
- Low value (close to 0): More predictable responses and focused on the most likely text.
Top P (or threshold probability)
The “Top P” parameter controls the diversity of responses by eliminating tokens that have a cumulative probability lower than a certain threshold. In other words, it filters out less likely options, which can be helpful in avoiding unexpected or inconsistent answers.
- High value: More diversity in responses, but increased risk of inconsistency.
- Low value: More focused and predictable responses.
Maximum length and stopping sequences
“Maximum length” defines the maximum number of tokens the model can generate in response to a prompt. “Stop sequences” are strings that tell the model where to stop generating text.
- Maximum length: Controls the length of the output.
- Stop Sequences: Tells the model where to end the response.
Frequency penalty and presence penalty
These settings allow you to customize the originality and diversity of the model output. The “frequency penalty” reduces the probability of tokens that appear frequently in the generated text, while the “presence penalty” increases the probability of tokens that have not yet been used.
- Frequency Penalty: Reduces redundancy in responses.
- Attendance penalty: Encourages diversity and originality of responses.
These settings provide granular control over the model’s behavior, allowing you to adjust the output to suit your specific needs. Understanding these parameters can greatly improve the quality of answers you get from the model.
OpenAI Playground Pricing
Language models
- GPT-4 Model: For prompts and completions, the price per 1000 tokens is $0.03 and $0.06 for an 8K context, and $0.06 and $0.12 for a 32K context respectively.
- ChatGPT Model: The price per 1000 tokens is $0.002.
- InstructGPT model: Depending on the model, the price per 1000 tokens varies from $0.0004 (Ada model) to $0.0200 (Davinci model).
Specialized models
- Fine-tuned Models: The price for fine-tuned models depends on the number of tokens used for training and usage. For example, for the Ada model, the price per 1000 tokens for training is $0.0004, and for usage it is $0.0016.
Other models
- Embedding Models: The price per 1000 tokens varies from $0.0004 (Ada v2 model) to $0.2000 (Davinci v1 model).
- Image Models: Depending on the resolution, the price per image varies from $0.016 (256×256) to $0.020 (1024×1024).
- Audio models: The price for the Whisper model is $0.006 per minute.